Aplicação de Hierarchical Risk Parity (HRP) nos Fatores de Risco da Bolsa Brasileira
Fatores de Risco
O NEFIN (Núcleo de Pesquisa em Economia Financeira) disponibiliza séries históricas dos fatores de risco da bolsa brasileira, sendo eles:
- Rm_minus_Rf -> Fator de mercado
- SMB -> Tamanho
- HML -> Valor
- WML -> Momentum
- IML -> Liquidez
Através da biblioteca {nefindata} do Fernando Martinello Ramacciotti, é possível obter essas séries históricas no R.
devtools::install_github('fernandoramacciotti/nefindata/R-package')
library(devtools)
library(nefindata)
library(dplyr)
library(ggplot2)
library(tidyr)
factor_df <- get_risk_factors(factors = "all",
agg = "day")
factor_df %>%
filter(year <= 2020) %>%
mutate(date = as.Date(paste(year, month, day, sep = "/"))) %>%
arrange(date) %>%
mutate(across(-c("year", "month", "day", "date"), ~ cumprod(1 + .x) - 1)) %>%
pivot_longer(-c("year", "month", "day", "date"),
names_to = "factors") %>%
ggplot(aes(date, value)) +
geom_line(aes(col = factors))+
theme_bw()+
labs(title = "Fatores de Risco (2001 - 2020)",
x = "Data",
y = "Retorno")
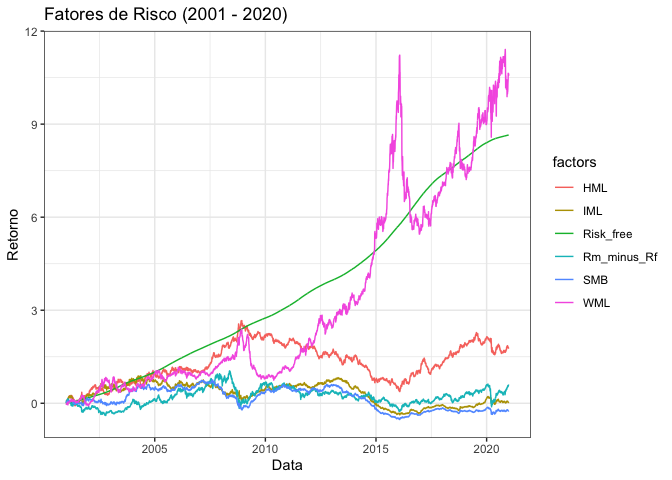
Existe uma discrepância bem grande entre Momentum e os outros fatores, sendo o único que superou o CDI no período.
Hierarchical Risk Parity
Marcos López de Prado propôs um algoritmo de paridade de risco
utilizando Hierarchical Tree Clustering (BUILDING DIVERSIFIED
PORTFOLIOS THAT OUTPERFORM
OUT-OF-SAMPLE).
O algoritmo será usado para alocar os fatores de risco em um
portfolio.
Abaixo, estão as funções que realizam a alocação de pesos através de
Matrix Seriation e Recursive Bisection. As funções foram retiradas
do
r-bloggers.
getIVP <- function(covMat) {
invDiag <- 1/diag(as.matrix(covMat))
weights <- invDiag/sum(invDiag)
return(weights)
}
getClusterVar <- function(covMat, cItems) {
covMatSlice <- covMat[cItems, cItems]
weights <- getIVP(covMatSlice)
cVar <- t(weights) %*% as.matrix(covMatSlice) %*% weights
return(cVar)
}
getRecBipart <- function(covMat, sortIx) {
# keeping track of w in the global environment
assign("w", value = rep(1, ncol(covMat)), envir = .GlobalEnv)
recurFun(covMat, sortIx)
return(w)
}
recurFun <- function(covMat, sortIx) {
subIdx <- 1:trunc(length(sortIx)/2)
cItems0 <- sortIx[subIdx]
cItems1 <- sortIx[-subIdx]
cVar0 <- getClusterVar(covMat, cItems0)
cVar1 <- getClusterVar(covMat, cItems1)
alpha <- 1 - cVar0/(cVar0 + cVar1)
# scoping mechanics using w as a free parameter
w[cItems0] <<- w[cItems0] * alpha
w[cItems1] <<- w[cItems1] * (1-alpha)
if(length(cItems0) > 1) {
recurFun(covMat, cItems0)
}
if(length(cItems1) > 1) {
recurFun(covMat, cItems1)
}
}
Serão utilizados os dados entre 2001 e 2020, sendo testado ano a ano com a alocação utilizando um conjunto de treinamento de todos os anos anteriores. Assim, o teste do ano de 2002 será alocado com base nas correlações e covariâncias de 2001 e o teste do ano de 2020 será alocado com todos os dados entre 2001 e 2019.
year_train <- seq(2001, 2019)
year_test <- year_train+1
factor_df <- nefindata::get_risk_factors(factors = "all",
agg = "day") %>%
mutate(date = as.Date(paste(year, month, day, sep = "/")))
#Empty dataframe
returns_df <- data.frame(Rm_minus_Rf = as.numeric(),
SMB = as.numeric(),
HML = as.numeric(),
WML = as.numeric(),
IML = as.numeric(),
Portfolio = as.numeric()
)
#Empty dataframe
volatility_df <- data.frame(Rm_minus_Rf = as.numeric(),
SMB = as.numeric(),
HML = as.numeric(),
WML = as.numeric(),
IML = as.numeric(),
Portfolio = as.numeric()
)
O loop abaixo calcula os retornos e a volatilidade dos fatores de risco e do portifólio usando HRP e os armazena nos dataframes returns_df e volatility_df.
for (i in 1:length(year_train)) {
factor_df_train <- factor_df %>%
filter(year %in% year_train[1:i])
factor_df_test <- factor_df %>%
filter(year == year_test[i])
correlation_matrix_train <- factor_df_train %>%
select(-c("year", "month", "day", "date", "Risk_free")) %>%
cor()
covariance_matrix_train <- factor_df %>%
select(-c("year", "month", "day", "date", "Risk_free")) %>%
cov()
#Hierarchical Cluster Order
clust_order_train <- hclust(dist(correlation_matrix_train), method = "single")$order
#Get weights
weights <- getRecBipart(covariance_matrix_train, clust_order_train)
final_portfolio <- factor_df_test %>%
mutate(across(-c("year", "month", "day", "date", "Risk_free"), ~ .x + 1))
#Atribuindo pesos aos fatores
final_portfolio$Rm_minus_Rf[1] <- final_portfolio$Rm_minus_Rf[1]*weights[1]
final_portfolio$SMB[1] <- final_portfolio$SMB[1]*weights[2]
final_portfolio$HML[1] <- final_portfolio$HML[1] *weights[3]
final_portfolio$WML[1] <- final_portfolio$WML[1]*weights[4]
final_portfolio$IML[1] <- final_portfolio$IML[1]*weights[5]
final_portfolio <- final_portfolio %>%
mutate(across(-c("year", "month", "day", "date", "Risk_free"), ~ cumprod(.x))) %>%
mutate(portfolio = Rm_minus_Rf + SMB + HML + WML + IML - 1)
#Gráfico 2016
if (year_test[i] == 2018) {
plot_series <- factor_df_test %>%
mutate(across(-c("year", "month", "day", "date"), ~ cumprod(1 + .x) - 1)) %>%
mutate(Portfolio = final_portfolio$portfolio) %>%
pivot_longer(-c("year", "month", "day", "date"),
names_to = "factors") %>%
ggplot(aes(date, value)) +
geom_line(aes(col = factors))+
theme_bw()+
labs(title = "Fatores de Risco + Portfolio (2018)",
x = "Data",
y = "Retorno")
plot_weights <- data.frame(Peso = weights,
Fator = colnames(covariance_matrix_train)) %>%
ggplot(aes(x = "",
y = Peso,
fill = Fator))+
geom_bar(width = 1, stat = "identity")+
coord_polar("y", start=0)+
theme_void()+
labs(title = "Alocação (2018)")
}
volatility <- factor_df_test %>%
mutate(Portfolio = final_portfolio$portfolio) %>%
mutate(Portfolio = (1+Portfolio)/(1+lag(Portfolio))-1) %>%
mutate(Portfolio = ifelse(is.na(Portfolio), 0, Portfolio)) %>%
summarise(across(-c("year", "month", "day", "date", "Risk_free"), ~sd(.x)*sqrt(252)))
returns <- factor_df_test %>%
mutate(across(-c("year", "month", "day", "date"), ~ cumprod(1 + .x) - 1)) %>%
mutate(Portfolio = final_portfolio$portfolio) %>%
filter(date == max(date)) %>%
select(-c("year", "month", "day", "Risk_free", "date"))
returns_df <- returns_df %>%
add_row(Rm_minus_Rf = returns$Rm_minus_Rf,
SMB = returns$SMB,
HML = returns$HML,
WML = returns$WML,
IML = returns$IML,
Portfolio = returns$Portfolio
)
volatility_df <- volatility_df %>%
add_row(Rm_minus_Rf = volatility$Rm_minus_Rf,
SMB = volatility$SMB,
HML = volatility$HML,
WML = volatility$WML,
IML = volatility$IML,
Portfolio = volatility$Portfolio)
}
Abaixo, alguns gráficos sobre a alocação e os resultados em 2018.
library(gridExtra)
grid.arrange(plot_series, plot_weights, ncol = 2)
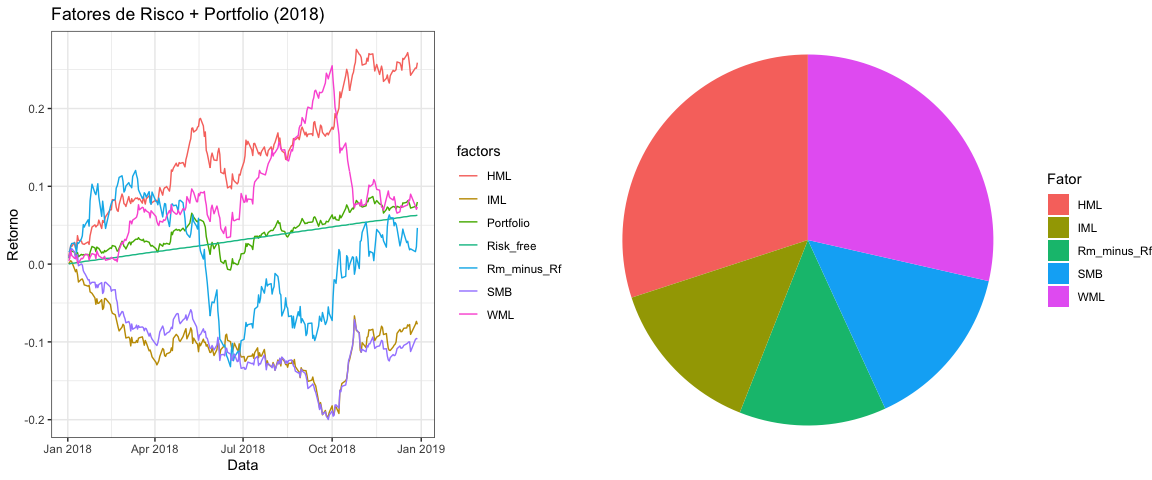
Calculando a média de retornos e de volatilidade, observa-se que os retornos do portfolio perdem apenas para o fator Momentum e possui a menor volatilidade entre os fatores citados.
returns_df %>% summarise_all(mean)
## Rm_minus_Rf SMB HML WML IML Portfolio
## 1 0.06040337 0.01443986 0.05589262 0.1769021 0.01065936 0.07865469
volatility_df %>% summarise_all(mean)
## Rm_minus_Rf SMB HML WML IML Portfolio
## 1 0.2374784 0.1437963 0.1321334 0.157687 0.1445289 0.07077947
Please, cite this work:
Wachslicht, Arthur (2022), “Aplicação de Hierarchical Risk Parity (HRP) nos Fatores de Risco da Bolsa Brasileira published at Open Code Community”, Mendeley Data, V1, doi: 10.17632/yzvt7wmn3r.1