Como baixar as cotas diárias dos Fundos via CVM
Introdução
Nesse post iremos apresentar um code para baixar os dados dos fundos através do csv disponbilizados pela CVM. Então os passos que serão aprendidos neste post são:
- Tratamento de datas
- Baixar csv através de links
- Fazer um append em um data.frame de diversos csv
- Filtrar dados
Primeiramente iremos baixar os pacotes utilizados no código.
rm(list = ls())
library(readxl)
library(readr)
library(tidyverse)
Iremos tratar os dados, alterando formatos de datas.
#Data de hoje
data = Sys.Date()
#Data de Ano AtuaL
data_2 = format(data,"%Y")
# Data do Mês atual
data_month = as.numeric(format(data,"%Y%m"))
Fazendo uma matriz com 12 observações. Usaremos 12 meses como exercício. No caso iremos fazer 12 meses anteriores a data de hoje. Exemplo: Hoje é 12/05/2021. Portanto, o mês e ano será 05/21, como são 12 observações anteriores, teremos 04/21 e assim sucessivamente.
data_month_12 <- seq(as.Date("2020-07-01"), as.Date(data), by = "months")
data_month_12 = paste0(year(data_month_12),format(data_month_12,"%m"))
#cria url com endereco para pegar os dados de dados diários (12 meses)
address<-paste0("http://dados.cvm.gov.br/dados/FI/DOC/INF_DIARIO/DADOS/inf_diario_fi_",data_month_12,".csv")
#cria url com endereco para pegar as informações dos fundos
address2 = paste0("http://dados.cvm.gov.br/dados/FI/DOC/EXTRATO/DADOS/extrato_fi_",data_2,".csv")
#Read CSV das informações dos fundos
dados_2<-read.csv2(address2,stringsAsFactors = F)
#Selecionar as colunas
dados_2 = dados_2 %>% select(CNPJ_FUNDO,DENOM_SOCIAL,CLASSE_ANBIMA)
Criando uma datalist para leitura de todos os csv, e depois fazendo um append em um dataframe com todos csv. Como baixamos cvs por mês, iremos baixar os dados diários do mês 05/21, depois iremos baixar 04/21, e fazer um append desses dados. Caso o leitor tenha uma forma mais eficiente para realizar essa tarefa, por favor envie uma mensagem para o autor desse post Gerson. Usaremos no for i in 1:2 para pegar esses mês e o mês anterior, usaremos apenas 2 meses como exercício, dado que o processo é lento. Iremos em próximos posts criar um maneira eficiente de baixar 1 vez os dados e apenas fazer o download da data mais recente. Caso queira fazer do ano inteiro é só alterar i in 1:2 para i in 1:12.
#Criar datalist
datalist = list()
#Baixar os csv de 12 meses
for (i in 1:2) {
# ... make some data
dados <- data.frame()
dados = read.csv2(address[i],stringsAsFactors = F)
datalist[[i]] <- dados # add it to your list
}
# Append de cada dataframe, cada dataframe são os dados diários de cada mês
big_data = do.call(rbind, datalist)
Essa parte iremos fazer um join do dados dos fundos e do csv que apresenta o nome do fundo e classificação anbima. Uma coisa interessante é saber a diferença entre left_join, inner_join, join e right_join.
# Join dos dados diários com os dados dos fundos, para linkar o nome dos fundos e classificação anbima
big_data = left_join(big_data, dados_2, by="CNPJ_FUNDO")
# Ordenando os vetores
big_data = big_data[,c(1,10,11,2,3,4,5,6,7,8,9)]
O código abaixo é para filtrar os fundos pela classificação anbima, filtrando todas as classificações de FIA. Podemos reparar muitos fundos não tem classificação anbima e nome, esse fato se deve ao csv do fundo não ter correspondência, caso o leitor tenha alguma outra sugestão de realizar esse papo de uma melhor forma.
# Filtrando os fundos por ação
big_data = big_data %>% filter(CLASSE_ANBIMA == "AÇÕES - ATIVO - LIVRE" | CLASSE_ANBIMA == "AÇÕES - ATIVO - VALOR / CRESCIMENTO"| CLASSE_ANBIMA == "AÇÕES - INVESTIMENTO NO EXTERIOR"|CLASSE_ANBIMA == "AÇÕES - MONO AÇÃO"| CLASSE_ANBIMA == "AÇÕES - FUNDOS FECHADOS"| CLASSE_ANBIMA == "AÇÕES - ATIVO - ÍNDICE ATIVO" | CLASSE_ANBIMA == "AÇÕES - ATIVO - SETORIAIS" | CLASSE_ANBIMA == "AÇÕES - ATIVO - DIVIDENDOS" | CLASSE_ANBIMA =="AÇÕES - INDEXADO - ÍNDICE PASSIVO")
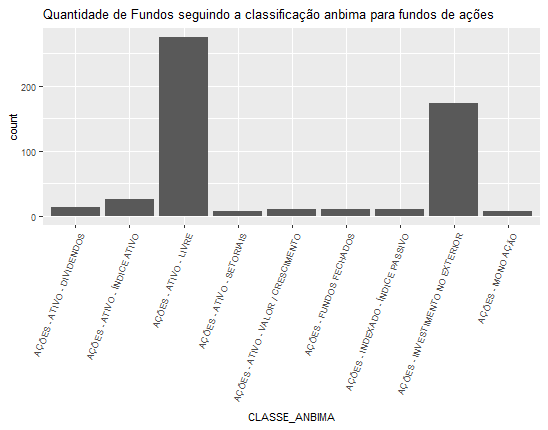
Frequência das classes dos fundos.
Freq = as.data.frame(table(big_data$CLASSE_ANBIMA))
Um plot com o histograma das classes dos fundos. Observação, como a variável é discreta teremos que usar geom_bar, se fosse continua, seria geom_histogram.
ggplot(big_data, aes(CLASSE_ANBIMA)) + geom_bar() + theme(text = element_text(size=8),
axis.text.x = element_text(angle=70, hjust=1)) +ggtitle("Quantidade de Fundos seguindo a classificação anbima para fundos de ações")
Vamos começar a lançar uma série de posts sobre fundos, caso tenha alguma sugestão, envie para os autores.
Please, cite this work:
Modeira, Igor; Junior, Gerson (2022), “Como baixar as cotas diárias dos Fundos via CVM published at Open Code Community”, Mendeley Data, V1, doi: 10.17632/f2s64wyhy5.1