Introdução ao dplyr
Introdução ao dplyr published at the "Open Code Community"
Nesse post iremos ensinar algumas funções do pacote dplyr, usado para manipulação de dados.
O objetivo é que esse post sirva como introdução e material de consulta para os iniciantes em R.
Utilizaremos o pacote gapminder como fonte dos dados que manipularemos. Esse é um pacote que contém dados socioeconômicos para diversos países em diversos anos, o que nos possibilita realizar as principais tarefas de manipulação de dados com o R: filter e mutate.
library(gapminder)
library(dplyr)
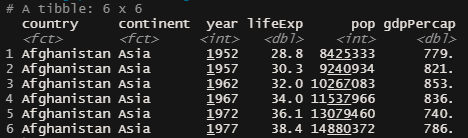
Visualizaremos como é o dataframe que estamos tratando.
head(gapminder)
Filter
Podemos, agora, fazer uso da função filter, para que selecionemos apenas algumas linhas de interesse do DataFrame. Usaremos também a função %>% (pipe) do dplyr.
# Nesse caso estamos filtrando o DataFrame para termos apenas as observações de
# dados em que o ano seja 2007.
# Note que usamos o comando %>%, que é uma maneira de aninhar as funções de uma
# forma a simplificar a visualização do nosso código.
# Esse comando faz parte do pacote dplyr.
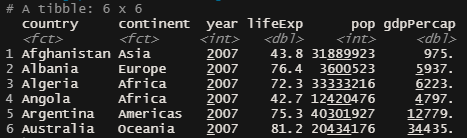
gapminder2007 = gapminder %>% filter(year == 2007)
head(gapminder2007)
Ao fazer isso, o filter seleciona as linhas do DataFrame que atendem à uma determinada condição estabelecida pelo usuário.
Agora, podemos analisar o comando mutate.
Mutate
Por vezes, não temos os dados da forma que os necessitamos. Para solucionar esse problema, podemos usar o mutate. Com o mutate podemos modificar uma coluna ou adicionar uma nova a partir das já existentes.
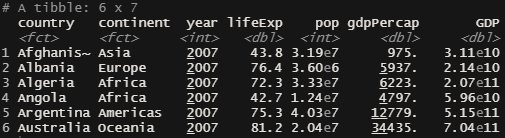
Digamos que você queira saber o valor dos PIBs para os países do dataframe. Contudo, só temos as informações de PIB per capita e população. Felizmente, podemos obter o PIB ao multiplicar essas 2 colunas.
gapminderGDP2007 = gapminder2007 %>% mutate(GDP = pop*gdpPercap)
head(gapminderGDP2007)
Transmute
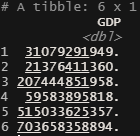
O transmute é muito similar ao mutate visto anteriormente, porém, ele tem uma propriedade peculiar que é apenas retornar a coluna que foi criada/modificada. As outras colunas não estão presentes no retorno.
Utilizando o mesmo exemplo que acima:
gapminderGDP2007tsmt = gapminder2007 %>% transmute(GDP = pop*gdpPercap)
head(gapminderGDP2007tsmt)
Select
Agora podemos analisar o uso da função select. A função, como o nome já indica, seleciona colunas do DataFrame a partir dos parâmetros passados, como por exemplo o nome das colunas. Há algumas subfunções muito úteis presentes na documentação da função, que permitem fazer seleções mais elaboradas que apenas com base no nome.
Nesse caso, por questões de simplicidade, iremos ilustrar o select selecionando colunas com base no seu nome.
gapminderGDP2007_Select = gapminderGDP2007 %>% select(continent, lifeExp, GDP)
head(gapminderGDP2007_Select)

Group_by e Summarize
A função group_by é incrívelmente útil para juntar (ou agrupar) um DataFrame com base um determinadas caracteristicas. Tipicamente ele é muito usado em conjunto com a função summarize, pelo seu grande poder combinado de descrição.
No exemplo que usaremos, o group_by será usado para agrupar o DataFrame com base nos diferentes continentes, ou seja, haverá um grupo contendo as linhas referentes à Europa, outro para as da África, e assim em diante.
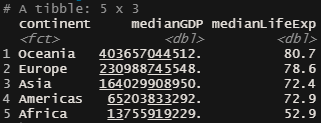
O summarize entra em cena já que desejamos descobrir para cada grupo (nesse caso, os continentes) qual é a mediana de seus valores de PIB (GDP) e de Expectativa de Vida (lifeExp).
Essa ferramenta pode ser muito útil em diversas análises.
gapminderGDP2007_SelectGroupBy = gapminderGDP2007_Select %>%
group_by(continent) %>% summarize(medianGDP = median(GDP), medianLifeExp = median(lifeExp))
head(gapminderGDP2007_SelectGroupBy)

Arrange
O arrange é uma função que ordena as linhas do dataframe de maneira crescente por meio dos valores de determinada coluna.
No exemplo abaixo, contudo, queremos ordenar as linhas de maneira decrescente, logo, precisamos passar como parâmetro a função desc().
# Teremos, agora, as linhas organizadas em valores decrescentes de mediana dos valores de PIB (medianGDP).
head(gapminderGDP2007_SelectGroupBy %>% arrange(desc(medianGDP)))
Please, cite this work:
Queiroz, Felipe; Medeiros, David (2021), “Introduçãao dplyr published at the “Open Code Community””, Mendeley Data, V1, doi: 10.17632/wpgpcfxxbs.1