Sentiment Analysis of 10-K Files
Sentiment Analysis of 10-K Files published at the "Open Code Community"
In this code we are going to develop a sentiment analysis algorithm to count the frequency of negative words on 10-K files. We will use Python to write the code.
Downloading 10-K files
In this section we are going to download 100 10-K files from the SEC Edgar website. To do that, we need to download an index file from the following website: https://www.sec.gov/Archives/edgar/full-index/2021/QTR1/. The file is called “company.idx” and has the names, date, and link from all financial reports in 2021.
With this file in hand, we are going to write a command to download the first 100 10-K files that appear on the list.
# Open the company idx file
index_file = open("company.idx").readlines()
#Just confirming the header of the file
print(index_file[:10])

Now are going to look for the link information. We first look for the 100 first lines that represent 10-K files.
# We will keep the information from this line in a list called find_list
find_list = []
item = 0
line = 0
while item < 100:
i = index_file[line]
loc1 = i.find('10-K')
loc2 = i.find("NT 10-K")
loc3 = i.find("10-K/A")
#We strictly keep 10-K files, not NT 10-K or 10-K/A
if (loc2 == -1) and (loc1 != -1) and (loc3 == -1):
find_list.append(i)
line+=1
item = len(find_list)
# Sanity check: if the command worked properly, the list should have 100 items.
print(len(find_list))
Now, from the 100 lines that we kept, we split the lines into pieces.
Recall that each line has the name of the firm, the CIK code, the date of the report, and the link to download it (the link is not complete, so we must add a prefix “https://www.sec.gov/Archives/").
# The commands below will split the line, and send the links to a list called ReportList, and the CIK+date issued to a list called
# Company_No (this will be the names of our files when we download them)
ReportList = []
Company_No = []
for i in find_list:
split_i = i.split()
ReportList.append("https://www.sec.gov/Archives/" + split_i[-1])
Company_No.append(split_i[-3] + "_" + split_i[-2])
print(ReportList[:5])
print(Company_No[:5])

We now create a function to save 10-K contents. The files will be saved into a folder called 10K Files.
import os
os.chdir("C:/Users/Victor/Desktop/Open Code/10K Text Mining/10K Files")
def createfile(filename, content):
name= filename + ".txt" # Here we define the name of the file
with open(name, "w") as file:
file.write(str(content)) # Here we define its content, which will be the textual content from the 10-K files.
file.close()
print("Succeed!")
Finally, here we will send the requests to the SEC website to download the 10-K files. The links are in the list ReportList and the names of the files are in the list Company_No.
import requests
company_order = 0
unable_request = 0
for a_index in range(100):
web_add = ReportList[a_index]
filename = Company_No[a_index]
webpage_response = requests.get(web_add, headers={'User-Agent': 'Mozilla/5.0'})
# It is very important to use the header, otherwise the SEC will block the requests after the first 5.
if webpage_response.status_code == 200:
# The HTTP 200 OK success status response code indicates that the request has succeeded.
body = webpage_response.content
createfile(filename, body)
else:
print ("Unable to get response with Code : %d " % (webpage_response.status_code))
unable_request += 1
a_index +=1
print(unable_request) # Check to see if any of the downloads failed! Luckily, none of them failed
# However, I strongly suggest that you check how many files the command downloaded because, more often than not, the company.idx
# has duplicates (for instance, when the same first release the same 10-K twice for whatever reason), so the command will not
# report an error, but it will not download all 100 files properly.
Cleaning the Text Before the Analysis
This section is extremely important. The good-practices standard book suggests that we should clean the text before analysing it. Since we are going to count the frequency of negative words, we do not want to inflate the denominator with meaningless words (like stop_words, punctuations, symbols, etc.).
Important note: Here I will show only the most basic cleaning. You can go much deeper into the text cleaning process. Just be careful to not clean it to a point where the contextual meaning is lost.
# First, we create a list with the name of the files in the folder where we downlaoded the 10-K files.
os.chdir("C:/Users/Victor/Desktop/Open Code/10K Text Mining/10K Files")
all_files = os.listdir()
# For the purpose of this exercise, I will use only 10 random files from the 100 we downloaded.
import random
# Here we basically create a list with 10 random indexes between 0 and 100 to selected the files in the folder.
random_index = []
while len(random_index) < 10:
n = random.randint(0,100)
if n not in random_index:
random_index.append(n)
# Here we create a new list with the 10 chosen files.
chosen_file = [all_files[i] for i in random_index]
print(chosen_file)

Creating a function to read the 10 randomly selected 10-K txt files.
def read_txt(file_name):
txt_file = open(file_name,"r",encoding='UTF8')
str_txt = txt_file.read()
return str_txt
Here we start the actual cleaning of the text.
It may seem a bit complicated, however, the steps do not change much for other types of text, so once you master it, you are good to deal with any kind of textual analysis.
First, we want to get only the meaningful textual content from the 10-K. The text comes full of technical sections, headers, many XML marks, etc. So, the first step, is to capture only what is inside the 10-K headers (which represents the actual 10-K content).
# We will use the regex module to get everything between these patterns: <DOCUMENT>\n<TYPE>10-K and </DOCUMENT>
# Using the regex modules it quite complex, so I recommend this long video for beginners: https://www.youtube.com/watch?v=AEE9ecgLgdQ&t=1092s
import re
text_start_pattern = re.compile(r'<DOCUMENT>')
text_end_pattern = re.compile(r'</DOCUMENT>')
type_pattern = re.compile(r'<TYPE>10-K[^\n]+')
# Here we will define a function that will be used to extract the textual data from 10-K txt files.
def textual_content(file):
doc_start_list = [x.start() for x in text_start_pattern.finditer(file)] #assigns the first index from the starting pattern created before
doc_end_list = [x.end() for x in text_end_pattern.finditer(file)] #assigns the last index from the ending pattern created before
type_list = [x[len('<TYPE>'):] for x in type_pattern.findall(file)] #assigns the type of the documents, which will always be 10-K's because we restricted it before
for doc_type, start_index, end_index in zip(type_list, doc_start_list, doc_end_list):
report_content = file[start_index:end_index]
return report_content
Lets run a sanity check using only 1 file
text_initial = read_txt(chosen_file[0])
text_10k = textual_content(text_initial)
print(text_10k[0:30])
print(text_10k[-30:])
# Yes, apparently the command is getting the right section of the text file, so we can move forward.

Now, lets clean the XML tags from before using the BeautifulSoup Python Module.
# https://www.crummy.com/software/BeautifulSoup/bs4/doc/
from bs4 import BeautifulSoup
def BeautifulSoup_clean1(str_txt):
soup = BeautifulSoup(str_txt,'html.parser')
return soup.get_text() # Here we return only the textual content, without the XML tags
Here we will remove punctuations and symbols (e.g., \n, ☐, ☒, \xa0, ●)
import string
from nltk.tokenize import word_tokenize
def further_clean(text):
# First, for each of the following characters (or symbols), the function replaces it by an empty space on the text
for a_sign in ['\\n', '\\t', '☐', '☒', '\xa0', '●', '“', '”']:
text = text.replace(a_sign," ")
# Here, for each punctution in a set of all existing punctuations, the function also replaces it by an empty space.
for a_punc in string.punctuation:
text = text.replace(a_punc, " ")
# Morever, the fuction replaces '\s+' (which represents a sequence of empty spaces) by an single empty space, avoiding unecessary spaces
# and also sets all letters to lower case to make it easier to analyse later.
text = re.sub('\s+'," ", text).lower()
return text.strip()
Tokenization
Here we will tokenize the text and do some more cleaning. Tokenizing means separating each word in the text. It is a crucial step given that we want to calculate the frequency of negative words, so we do not want to deal with the text itself, but with each word separately.
# Very important: This function here is for exposition only. It will be modified later in section 5 when we start using
# the dictionary of negative words.
# Tokenizing and counting the total frequency of words
from nltk.tokenize import word_tokenize
def word_count(text):
word_list = word_tokenize(text) #splits the text into words and assigns it to a new list
total_num = len(word_list) #count the number of words in the new list
return total_num, word_list
Important improvement steps that would are not used in this analysis:
To make this code easier for beginners, I will not run the two following steps that would improve the precision of the analysis. For the purposes of this tutorial, these commands are not essential and would make it considerably more complex.
- Removing Stop Words
- Lemmatizing the words
Importing a dictionary of Negative Words (Loughran & Mcdonald)
For this analysis, I will use the dictionary of negative words created by Loughran and Mcdonald.
The file with the dictionary can be downloaded from many different websites. I recommend downloading from this website: https://sraf.nd.edu/textual-analysis/resources/#Master%20Dictionary.
They have some instructions on how to use the dictionary, but just to make things a bit easier, you can edit the excel file to keep only the words that represent a negative sentiment, and delete all the others. Moreover, we just need the words, so you can remove all other columns from the excel file after you deleted words that are not flagged as negative.
If you have any trouble using the dictionary, just send me an email and I can help you out!
import pandas as pd
LM_negw = pd.read_csv("C:/Users/Victor/Desktop/Open Code/10K Text Mining/LM_negative_wordlist.csv")
# Transform the file into a list of negative words, and convert all entries to lowercase.
LM_negw = list(LM_negw['Negative_word'])
LM_negw = [j.lower() for j in LM_negw]
# Since we will be counting negative words, lets create a dictionary that assigns the number of appearances to each negative words
negw_dic = {} #creates an empty dictionary
for A_NegWord in LM_negw:
negw_dic[A_NegWord] = 0 # For each word in the LM_negw list, we create an entry inside the dictonary with the word and the number 0.
Counting Negative Words in the Text
Here we finally count the frequency of negative words in the 10 random 10-K files we selected. This analysis is called sentiment analysis, however, it is very basic in the way it is shown here. You can go much deeper by using not only negative, but words that represent other relevant sentiments.
# VERY IMPORTANT COMMENT. I WILL REDEFINE THE FUNCTION TO TOKENIZE THE TEXT AND WILL ADD THE STEPS TO COUNT THE NEGATIVE WORDS.
# THIS WAY, THE COMMAND WILL BE MUCH EASIER TO RUN
from nltk.tokenize import word_tokenize
def word_count(text):
# Tokenizing and counting total words
word_list = word_tokenize(text) # Splits the text into words and assigns it to a new list
total_num = len(word_list) # Count the number of words in the new list
# Counting negative words
negw_dic_ex = negw_dic.copy() # This commands creates a copy of the dictionary we created with the L&M negative word list
# This loops checks if each word in the text is a negative word, and if so, adds 1 to the respective entry in
# the "negw_dic_ex" dictionary.
for a_word in word_list:
if a_word in LM_negw:
negw_dic_ex[a_word] += 1
# This commands creates a new variable from a dictionary (the negw_dic_ex created before), and the orient="index" means that
# the keys of the dictionary will be the rows of the variable.
negw_df = pd.DataFrame.from_dict(negw_dic_ex, orient='index')
negw_df.reset_index(inplace=True) # This command modifies the indexes of the list, converting them to default indexes.
# This command renames the columns of the variable (inplace=True means that the variable will be modified without creating a new variable)
negw_df.rename(columns={"index": "Negative_words", 0: "Word_counts"}, inplace=True)
total_neg = sum(list(negw_dic_ex.values())) # Total number of negative words
negw_fre = total_neg/total_num # % of negative words in the text
return {"Negative_WordCount_df":negw_df, "Total_WordNumber":total_num, "Total_Negative_WordCount": total_neg,
"Negative_WordFrequency": negw_fre}
THE GRAND FINALE: Calling all functions and showing results in a table
# First, we open 4 empty lists to append the 4 returns from the function we've just defined.
Neg_WordDf_list = []
Total_Word_list = []
Total_Neg_Word_list = []
Frequency_list = []
# For each file in the chosen_file list (the list with the 10-K txt files)
for a_file in chosen_file:
text = read_txt(a_file) #run the read_txt fuction that opens the txt file
text = textual_content(text) #run the textual_content function to get the textual content from the file opened before.
text = BeautifulSoup_clean1(text) #run the BeautifulSoup_clean1 function to clean the data even better using the html.parser algorithm.
text = further_clean(text) #run the further_clean function to remove symbols, punctiations, and convert strings to lower case.
result = word_count(text) #run the word_count functions that tokenize the text, and deal with negative word counting.
Neg_WordDf_list.append(result['Negative_WordCount_df'])
Total_Word_list.append(result["Total_WordNumber"])
Total_Neg_Word_list.append(result["Total_Negative_WordCount"])
Frequency_list.append(result["Negative_WordFrequency"])
Plotting the results in a table.
# Here we create a new dictionary using data from the lists defined before.
summary = {'File_name':chosen_file, 'Total_WordNumber':Total_Word_list, 'Total_Negative_WordCount':Total_Neg_Word_list,'Negative_WordFrequency':Frequency_list}
summary_df = pd.DataFrame(summary, index=range(1,11))
summary_df
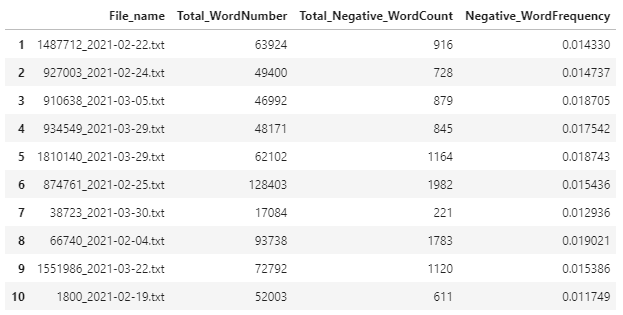
What to do with this data???
The data generated here can be used in many different settings. For instance, questions that are very interesting using the frequency of negative words in the 10-K are:
- Do investors react to suttle changes in the tone of financial reports?
- Can the textual analysis of financial reports improve the prediction of bankruptcy events?
- Do managers strategically manipulate the tone of the 10-K files?
Please, cite this work:
Dahan, Victor (2021), “Sentiment Analysis of 10-K Files published at the “Open Code Community””, Mendeley Data, V1, doi: 10.17632/8nv274mp7s.1